LLM at Edge: LLM inference locally with Llama CPP and Gemma 9B model
Architecture
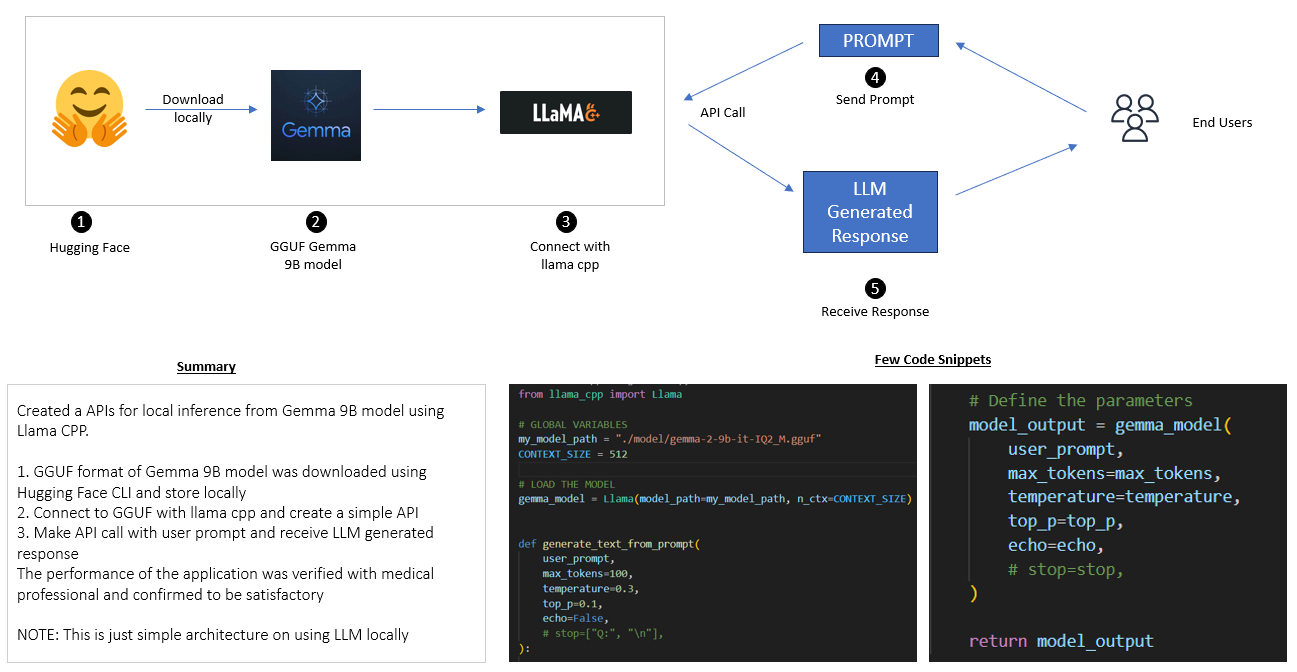
Key features
- Local LLM inference with Gemma 9B (GGUF) — no cloud API dependency
- Model downloaded locally and offline deployment
- Simple API to interact with the model
- Configurable generation parameters — max tokens, temperature, and top_pli>